Qwent-Finance is a fully self-hosted portfolio-analytics workbench I built to answer one question honestly: can a modern zero-shot time-series foundation model say anything genuinely useful about my holdings? It pairs a local stock-trend visualizer with Chronos-2 probabilistic forecasts, a rigorously backtested findings tab, an AI investment council that deliberates over the live signals, and a practice game that turns the model into something you can actually play against. Everything runs on my own machine on my own GPU — no data ever leaves the box — and it is emphatically not financial advice.
Why it's interesting. Two threads I care about meet here: self-hosting (private financial data stays local, a 120M-param forecaster runs on a consumer RTX GPU at ~20 ms/forecast, and the whole thing plugs into my own AI workspace) and epistemic honesty in quantitative finance — every backtested claim carries an adversarially verified verdict, and the headline result is a negative one I trust more than a positive one I don't.
What it does.
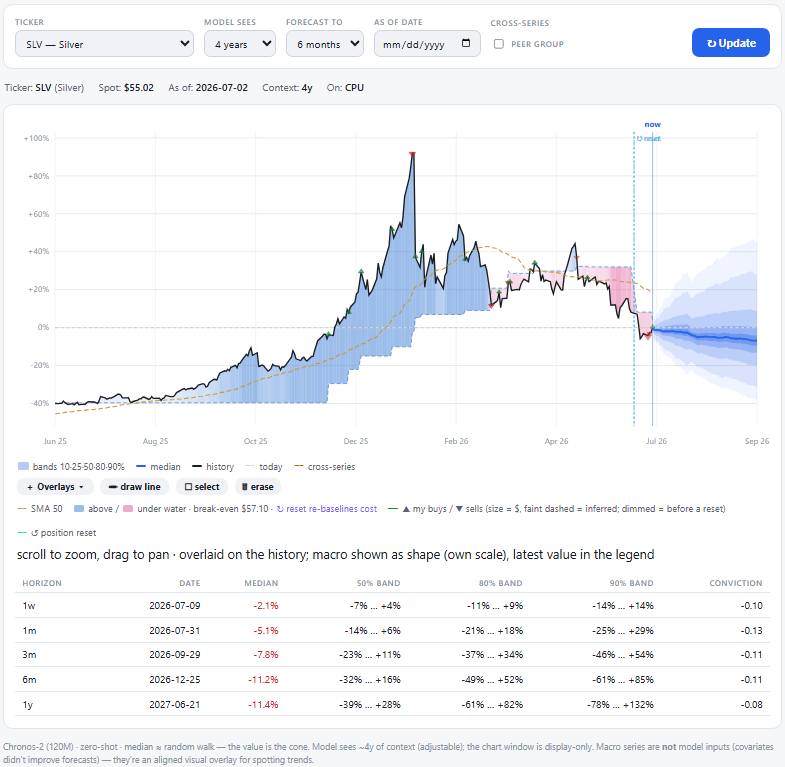
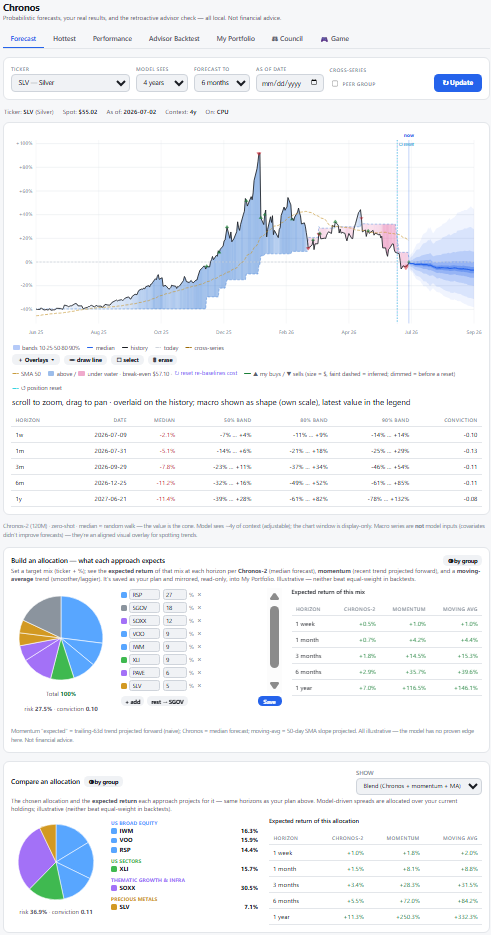
- Forecast — price history with the Chronos-2 cone, a unified overlay menu (SMA 50/200, volatility, momentum, two vol-regime shadings, macro-context series from FRED), and an editable allocation builder showing expected return per horizon under Chronos vs momentum vs moving-average.
- Hottest — a sortable watchlist of ~28 tickers: volatility flags, Chronos / momentum / MA columns per horizon, and trailing 1w / 1m / 3m moves.
- Performance — every backtested finding with an explicit verdict (the section this write-up is really about).
- Advisor Backtest & My Portfolio — drop in your own trades for a FIFO realized/unrealized breakdown and a no-look-ahead “would the model have agreed?” check.
- Council — an AI committee that deliberates and issues a target allocation (below).
- Game — an anonymized allocation game you play against equal-weight (below).
What we actually found
The Chronos advisor was evaluated with rolling-origin, point-in-time backtests (~1,300 forecasts per config) and an adversarial verification loop — every claim below was recomputed independently and stress-tested. The findings are candid, and most of the “exciting” ones are exciting because they refute a tempting idea:
- calibrated The cone is a well-behaved second opinion. Best config (single-series) gets ~56% direction and +3.8%/call — real, but a low ~0.14 Sharpe: honest about its own uncertainty rather than pretending to an edge.
- insight Conviction is a setup detector, not an oracle. Sorting forecasts by conviction (|expected move| ÷ cone width), the top quintile hits 66% direction vs 55% for the bottom — “only act when the model is convinced” roughly doubles the edge. Verified caveat: as a long-only precision gate the lift is only ~+2pp (90% CI [−3, +7]) and it reverses in 2022 — so it ships as a soft tilt, not a win-rate guarantee.
- refuted Market-timing makes things worse. “Hold when bullish, cash when bearish” turned 2022's −8% into −27% — it held the drops and cashed the rebounds. Do not deploy.
- refuted There is no profitable sell signal. Across 28 ETFs the reward-optimal policy is literally “never actively sell” (27/28); active exits run about −4.5%/yr on a time-in-market basis.
- no skill No stock-picking ability. Ranking the universe by Chronos metrics has a negative information coefficient — it tilts toward the laggards.
- no edge Equal-weight wins. Under a softmax allocation over any metric, uniform 1/N is Sharpe-optimal; concentrating via Chronos lowers return. Diversification dominates selection.
- dead The “learn when to trust it” gate failed. A meta-labeling adapter had out-of-sample AUC ~0.47–0.51 (indistinguishable from noise) — too few genuinely independent events to learn from.
- honest Memorization caveat. Chronos-2's weights postdate ~Oct 2025, so pre-2025 backtests aren't truly out-of-sample — read as optimistic. The one clean test still open is a forward paper-trade through a real drawdown.
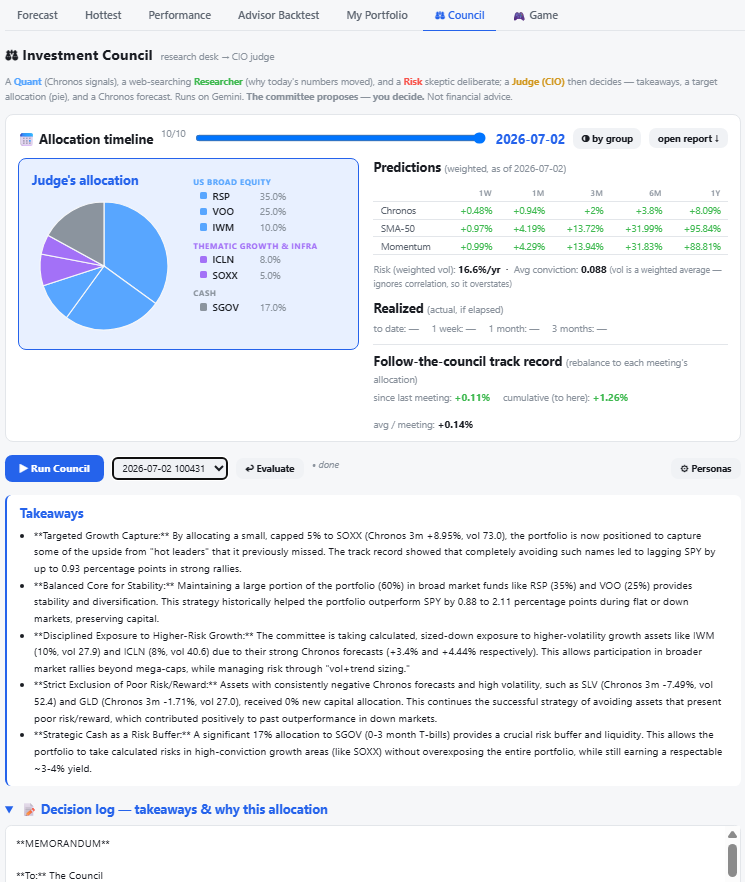
Council — an AI investment committee
A one-button committee deliberates over the live signals on Gemini: a Quant (Chronos only), a web-grounded Researcher (why today's names moved, cited), a Risk skeptic, and a CIO Judge who issues a ≤10-position target allocation using SGOV as an earning cash/hedge sleeve. A note-taker keeps a credited decision log, and a retrospective feeds past calls' realized performance back in so the committee learns from its own track record. It's portfolio-blind — it sees the market briefing and Chronos signals, never my holdings — and runs entirely on its own (no external workspace required).
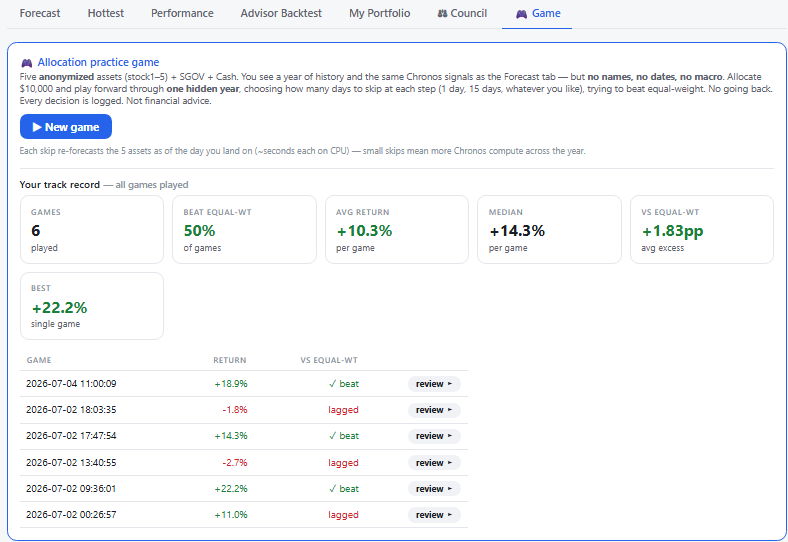
Game — play against the model
The most honest test of “is this useful?” is whether you can allocate better with the signals than without. The allocation practice game hands you five anonymized assets (plus cash) with a year of history and the same Chronos signals as the Forecast tab — but no names, no dates, no macro — and asks you to play forward through one hidden year, trying to beat equal-weight. Every decision is logged and scored against the 1/N benchmark, so the track record accumulates as genuine, bias-controlled evidence.
Stack & self-hosting. Python + Flask serve the app locally; Chronos-2 runs on a consumer NVIDIA GPU (CPU fallback); prices come from yfinance and macro series from FRED; the council uses the Gemini API (optional local Ollama / Groq routing). It optionally embeds inside my self-hosted AI workspace via an iframe, but the full app — council and game included — runs standalone.
Code: github.com/Quentin-Fruytier/qwent-finance (open-source, MIT). Runs entirely locally — not financial advice.